


Introduction
In the summer of this year, I had the opportunity to participate in a course titled “Introduction to the Fundamentals of Artificial Intelligence,” held by the Artificial Intelligence Community at the University of Isfahan. This course opened a practical and structured window into the vast world of AI, showing us how artificial intelligence thinks and solves problems across its various branches.
Course Instructor: Abolfazl Ranjbar

The course was taught by Mr. Abolfazl Ranjbar, a Computer Engineering student at the University of Isfahan and an active member of this community. His main expertise lies in the fields of Large Language Models (LLMs) and Reinforcement Learning, and he is currently working on a practical project involving “Automated ICD Coding using LLMs with MIMIC datasets.” His command and eloquence in teaching complex concepts made understanding these fundamentals significantly easier.
What is CUBE?

This course was named CUBE. This simple yet symbolic name represented the four fundamental pillars of learning in this field: Coding, Understanding, Building, and Exploration. The philosophy of CUBE taught us that to master artificial intelligence, theory alone is not enough; we must be able to code, deeply understand concepts, build real projects, and always maintain an inquisitive spirit.
Data Analysis with Python
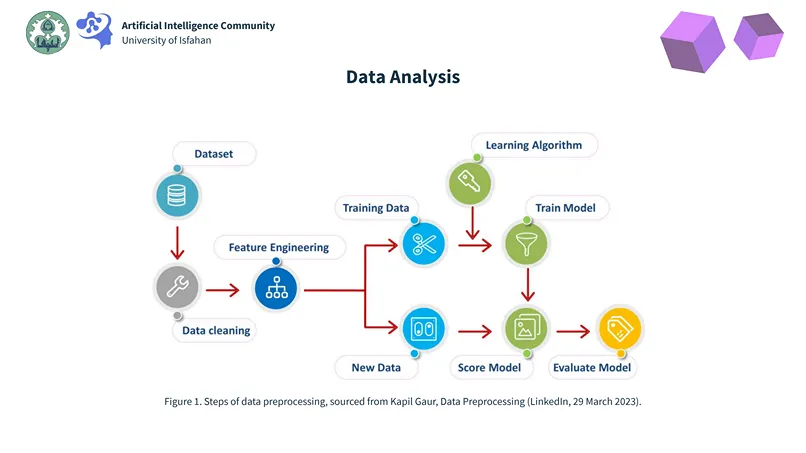
Our learning journey began with the most fundamental and critical element: Data. We learned that before any complex model, we must first understand the language of data.
This section introduced the essential toolkit for working with data. Key topics included foundational statistical concepts such as Expected Value, Cumulative Distribution Function (CDF), and Probability Density Function (PDF). We then explored practical skills for making data understandable, starting with Data Visualization using Python libraries, which allowed us to draw various charts and graphs.
A major focus was on preparing raw data for analysis through Data Cleaning and Data Preprocessing—vital steps to ensure data quality. Finally, we learned the art of Exploratory Data Analysis (EDA), a detective-like process to uncover patterns, spot anomalies, and extract initial insights from data. This entire module established the crucial foundation that every machine learning project is built upon.
Machine Learning: Starting with Regression
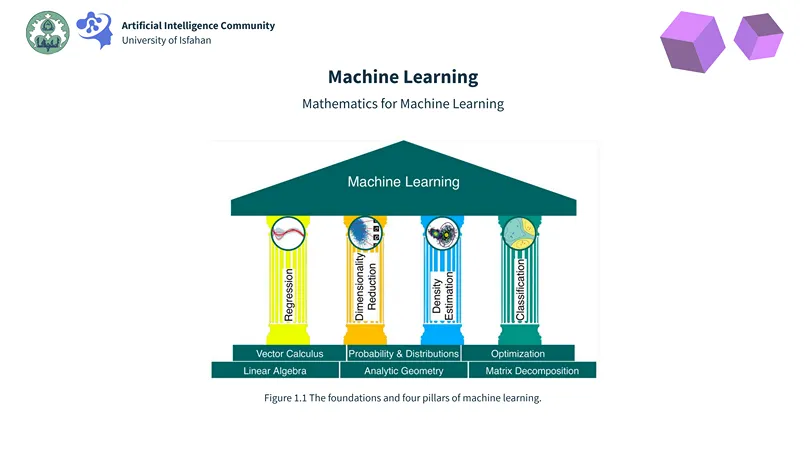
After establishing a solid foundation in data analysis, we entered the core of artificial intelligence: Machine Learning. Our first major topic was Regression, a fundamental technique for predicting continuous values.
In this section, we started with the intuitive concept of Linear Regression, which models the relationship between variables as a straight line. We then explored Polynomial Regression, a more flexible approach that fits a curved line (polynomial) to capture non-linear relationships in the data.
A critical part of the discussion was understanding the fundamental challenge of modeling: the balance between simplicity and accuracy. We learned about Overfitting and Underfitting—where a model is either too complex (memorizing the noise in training data) or too simple (failing to capture the underlying trend). Understanding this trade-off was key to building models that generalize well to new, unseen data. This module provided our first practical toolkit for making predictions and understanding how machines “learn” from data.
The Engine of Learning: Optimization
Building upon our understanding of models like regression, we delved into the mathematical engine that powers machine learning: Optimization. This crucial section addressed the “how” behind a model’s learning process—how it finds the best possible parameters.
We began by understanding why direct methods like the Normal Equation can be inefficient or impractical for complex models and large datasets. This led us to the world of iterative optimization algorithms.
Key conceptual distinctions were covered, such as:
- Local vs. Global Optimization: The challenge of finding the best possible solution versus a good solution in a specific region
- Constrained vs. Unconstrained Optimization: Problems with limitations (constraints) versus those without.
- Convex vs. Non-convex Problems: Understanding the landscape where convex problems guarantee a single, global minimum, while non-convex surfaces have many potential pitfalls (local minima).
The core of this module was Gradient Descent, the foundational optimization algorithm. We broke down its mechanics: using the gradient to determine the descent direction (the steepest path downhill on the error surface) and the critical role of the learning rate—a step size that must be carefully chosen to ensure stable and efficient convergence toward the optimal solution. This framework provided the essential logic behind how models iteratively improve and learn from their mistakes.
Making Decisions & Finding Patterns: Classification & Clustering

Moving from predicting numbers to making decisions, we entered the world of Classification. This module focused on teaching machines to categorize data into distinct groups.
We connected this topic back to our optimization knowledge, using an objective function (like log loss) and gradient descent to train the models. A classic example was Spam Detection, demonstrating how a model learns to separate “ham” from “spam” emails. We also worked with the famous Iris dataset to classify flower species.
Key techniques included:
- Logistic Regression: A fundamental algorithm that uses the Sigmoid function to output probabilities for class membership.
- Multi-class Strategies: Methods like One-versus-All (OvA) to extend binary classifiers to problems with multiple categories.
- Non-linear Boundaries: Transforming a quadratic decision boundary into a linear one using feature engineering, showcasing the power of data representation.
- K-Nearest Neighbors (KNN): A simple, intuitive algorithm that classifies points based on the majority class of their closest neighbors.
Finally, we shifted to Unsupervised Learning with Clustering, where the goal is to discover inherent groupings in data without predefined labels. This completed our view of core machine learning paradigms, from learning with guidance (supervised) to exploring data structure independently (unsupervised).
Learning by Interaction: Reinforcement Learning
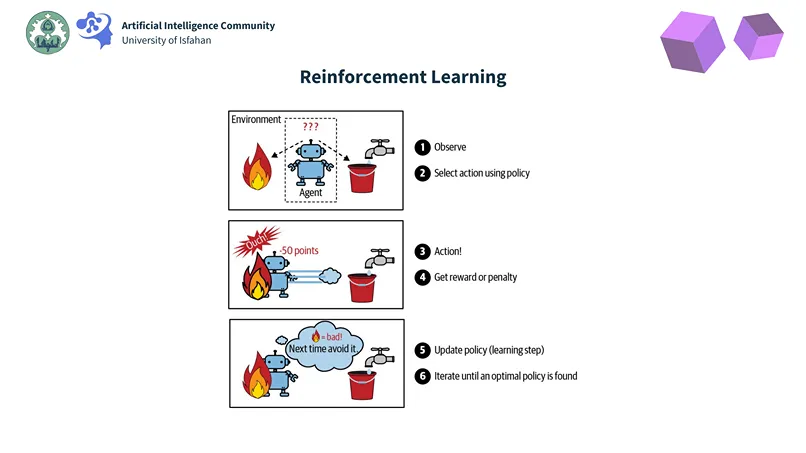
We then explored one of the most fascinating paradigms of machine learning: Reinforcement Learning (RL). This is where an agent learns to make optimal decisions by interacting with an environment, receiving rewards or penalties for its actions—much like learning to play a game.
We were introduced to the iconic example of AlphaGo, the AI that mastered the complex game of Go, showcasing RL’s power in Game environments. To build a foundational understanding, we started with simpler Learning Environments like the Grid World and the Vacuum World (and its more unpredictable variant, the Erratic Vacuum World). These served as perfect sandboxes to understand Sequential Decision Problems, where each choice affects future possibilities.
Key concepts to solve these problems were covered:
- Discounting: The idea of valuing immediate rewards more highly than future ones.
- Value Iteration: A fundamental algorithm that iteratively computes the expected long-term reward (value) of being in each state, guiding the agent toward the optimal policy.
This module opened our eyes to a different kind of intelligence—one built on trial, error, and strategic long-term planning, with applications far beyond games, into Robotics, NLP, and Generative AI.
Neural Networks & Deep Learning
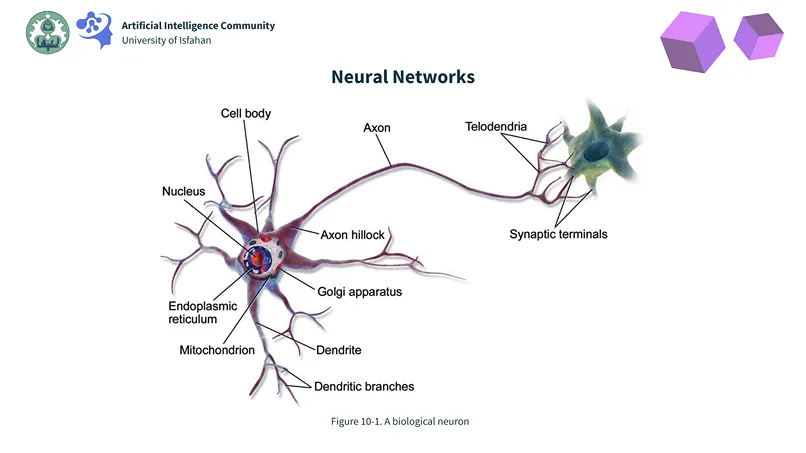
In this pivotal section, we moved beyond traditional algorithms to explore the architectures inspired by biological intelligence: Neural Networks. We started with their biological inspiration, drawing a parallel between artificial neurons and their biological counterparts.
Our journey began with the simplest unit, The Perceptron, and quickly scaled up to the Multi-Layer Perceptron (MLP). We learned how an MLP, by stacking layers, gains the power to compose complicated decision boundaries and model complex patterns that linear models cannot, even with just a single hidden layer.
A key application was extending this power to Multi-class Classification using a Neural Network with a Softmax function in the output layer, which converts scores into clear probability distributions over multiple classes.
We then delved into the crucial Training Phases that bring these networks to life:
- Forward Pass: Where input data is propagated through the network to generate a prediction.
- Backward Pass (Backpropagation): Where the error from the prediction is propagated backward through the network, allowing the model to learn by adjusting its weights.
This understanding laid the groundwork for Deep Neural Networks and the field of Deep Learning. We discussed the transformative impact of deep learning, exemplified by breakthroughs like the ImageNet competition, where deep networks dramatically surpassed all previous methods in computer vision, ushering in the modern era of AI.
Giving Machines Sight: Computer Vision

Building on the power of deep neural networks, we entered the field of Computer Vision—teaching machines to see, interpret, and understand the visual world. This module showcased the transformative real-world impact of AI across diverse industries.
We began by defining core Computer Vision Problems beyond simple classification, focusing on advanced scene understanding tasks:
- Semantic Segmentation: Labeling every pixel in an image with a class (e.g., road, car, pedestrian).
- Instance Segmentation: Identifying and delineating each distinct object of interest.
- Panoptic Segmentation: A unified task combining both semantic and instance segmentation.
The applications were brought to life through compelling examples:
- Self-Driving Cars: Relying on vision for pedestrian detection, parking occupancy detection, traffic flow analysis, and road condition monitoring.
- Healthcare: Revolutionizing diagnostics through X-ray analysis, cancer detection, blood loss measurement, and digital pathology.
- Manufacturing & Retail: Enhancing efficiency and quality in product assembly, defect inspection, and reading text and barcodes.
- Agriculture & Safety: Enabling precision farming via insect detection, automatic weeding, livestock health monitoring, plant disease detection, and automatic replenishment.
This section vividly illustrated how computer vision acts as the “eyes” of AI, creating intelligent systems that interact with and improve our physical environment.
Natural Language Processing
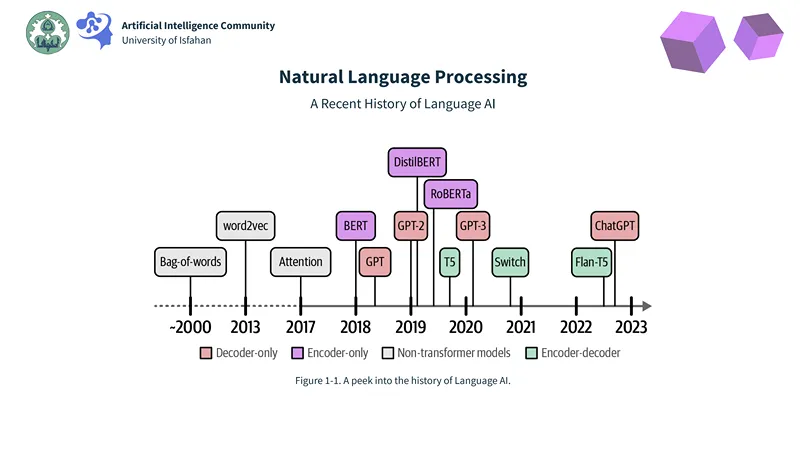
Our journey concluded by exploring how machines comprehend and generate human language through Natural Language Processing (NLP). We traced A Recent History of Language AI, witnessing its evolution to today’s powerful Autoregressive Language Models capable of remarkably fluent Generation.
The foundational challenge was How to Represent Words for a computer. We moved from simple, sparse methods like One-Hot Encoding to the revolutionary concept of Dense Vector Embeddings. Using metrics like Cosine Similarity, we saw how these embeddings place words with similar meanings close together in a multidimensional space, capturing semantic relationships.
We explored the practical tools of this transformation:
- Tokenizer: The component that breaks text into meaningful chunks (tokens).
- Approaches to Generate Embeddings: Learning how context-aware representations are created.
This led us to landmark models like BERT, which set new standards for language understanding, and ultimately to modern Generative Models and the practical skill of Interfacing with Large Language Models.
This final module connected all the dots—from foundational math to deep learning architectures—showing how they converge to create systems that can read, write, and converse, marking the frontier of human-machine collaboration.
My Certificate
